We not only need the ability to create descriptions of existing trees, we need to build trees from descriptions. In this section of the tutorial, we will ultimately create the function buildFromNewick, but first we need to create several helper functions that will be called from within buildFromNewick. For some of the functions, I depend on comments in the code itself to explain what is happening. So, if it feels that I’m not explaining things adequately, see if you can understand how the function works by reading the comments (lines starting with //) I’ve placed in the function body itself.
Add declarations to the TreeManip class
Start by including header files and adding declarations for all the methods we will need to the TreeManip class declaration in the file tree_manip.hpp. New additions are in bold, blue text:
#pragma once
#include <cassert>
#include <memory>
#include <stack>
<span style="color:#0000ff"><strong>#include <queue></strong></span>
<span style="color:#0000ff"><strong>#include <set></strong></span>
<span style="color:#0000ff"><strong>#include <regex></strong></span>
<span style="color:#0000ff"><strong>#include <boost/range/adaptor/reversed.hpp></strong></span>
#include <boost/format.hpp>
#include "tree.hpp"
<span style="color:#0000ff"><strong>#include "xstrom.hpp"</strong></span>
namespace strom {
class TreeManip {
public:
TreeManip();
TreeManip(Tree::SharedPtr t);
~TreeManip();
void setTree(Tree::SharedPtr t);
Tree::SharedPtr getTree();
double calcTreeLength() const;
unsigned countEdges() const;
void scaleAllEdgeLengths(double scaler);
void createTestTree();
std::string makeNewick(unsigned precision, bool use_names = false) const;
<span style="color:#0000ff"><strong>void buildFromNewick(const std::string newick, bool rooted, bool allow_polytomies);</strong></span>
<span style="color:#0000ff"><strong>void rerootAtNodeNumber(int node_number);</strong></span>
void clear();
private:
<span style="color:#0000ff"><strong>Node * findNextPreorder(Node * nd);</strong></span>
<span style="color:#0000ff"><strong>void refreshPreorder();</strong></span>
<span style="color:#0000ff"><strong>void refreshLevelorder();</strong></span>
<span style="color:#0000ff"><strong>void renumberInternals();</strong></span>
<span style="color:#0000ff"><strong>void rerootAtNode(Node * prospective_root);</strong></span>
<span style="color:#0000ff"><strong>void extractNodeNumberFromName(Node * nd, std::set<unsigned> & used);</strong></span>
<span style="color:#0000ff"><strong>void extractEdgeLen(Node * nd, std::string edge_length_string);</strong></span>
<span style="color:#0000ff"><strong>unsigned countNewickLeaves(const std::string newick);</strong></span>
<span style="color:#0000ff"><strong>void stripOutNexusComments(std::string & newick);</strong></span>
<span style="color:#0000ff"><strong>bool canHaveSibling(Node * nd, bool rooted, bool allow_polytomies);</strong></span>
Tree::SharedPtr _tree;
public:
typedef std::shared_ptr< TreeManip > SharedPtr;
};
Member function bodies
The bodies of the 2 new public and 8 new private member functions are described and listed below. Each of these should be copied into tree_manip.hpp just above the right curly bracket (‘}’) that terminates the namespace strom code block (this curly bracket is the last non-whitespace character in the file). If you accidentally copy one of these functions below that terminating right curly bracket, then your function body will be outside the namespace and will not be recognized as being part of the class. Just giving you a little “heads up” because (as per Murphy’s Law) this will happen to you at some point during the tutorial. If you ever get hopelessly lost in trying to figure out what went wrong, note that the source code for this step is available in the GitHub Strom repository, as is the code for every step in the tutorial, so download and compare your version to my version to find the problem.
The extractNodeNumberFromName member function
The program we are creating will only read newick tree descriptions in which taxa are represented by positive integers (normally representing their position in the data matrix, with the first taxon being 1). This private function converts the node name (a string representation of an integer greater than zero) into an unsigned integer. If the node name cannot be converted to a positive integer, an XStrom exception is thrown.
inline void TreeManip::extractNodeNumberFromName(Node * nd, std::set<unsigned> & used) {
assert(nd);
bool success = true;
unsigned x = 0;
try {
x = std::stoi(nd->_name);
}
catch(std::invalid_argument &) {
// node name could not be converted to an integer value
success = false;
}
if (success) {
// conversion succeeded
// attempt to insert x into the set of node numbers already used
std::pair<std::set<unsigned>::iterator, bool> insert_result = used.insert(x);
if (insert_result.second) {
// insertion was made, so x has NOT already been used
nd->_number = x - 1;
}
else {
// insertion was not made, so set already contained x
throw XStrom(boost::str(boost::format("leaf number %d used more than once") % x));
}
}
else
throw XStrom(boost::str(boost::format("node name (%s) not interpretable as a positive integer") % nd->_name));
}
The function std::stoi is used to do the conversion of string to integer. The std::stoi function throws a std::invalid_argument exception if the string passed to it cannot be converted to an integer. This allows us to give the user an accurate error message if we ever encounter a node whose name is not integer-like.
This function also adds tip node numbers to the set used. This allows us to provide important error information to the user if the same tip number is used more than once in the newick string. The more sanity checks you can put into your code, the less frustrated your users will be when they use your software. And remember, you yourself are probably going to be the most frequent user of your programs!
A word about exceptions
This is our first use of throwing and catching exceptions. The try block encloses code that you think may suffer from problems beyond your control (i.e. problems generated by your user misunderstanding how to use your program). If a problem is indeed encountered during execution of the code within the try block, an exception object is thrown. An exception object is normally an object (instance) of a class and, as such, may have data (e.g. information about the problem encountered) and methods (e.g. a method that, for example, converts the on-board data into a meaningful error message). Often, the exception class name of the exception object itself carries information about the nature of the problem. Here, if stoi cannot convert a string to an integer, it throws an invalid_argument exception. The type name invalid_argument tells you pretty much all you need to know.
The corresponding catch block contains code that is executed only if the type of exception for which the catch block is defined occurs. There can be multiple catch blocks, one for each possible type of exception, or one catch(...) block that covers all possible exceptions.
The extractEdgeLen member function
This private function serves to convert a string representation of an edge length (taken from the newick tree description string) into an actual edge length (i.e. floating point value).
The function std::stod is used to do the conversion of string to double. The std::stod function throws a invalid_argument exception if the string passed to it cannot be converted to a floating point number. This allows us to give the user an accurate error message if we ever encounter a string that cannot be converted to a valid edge length.
inline void TreeManip::extractEdgeLen(Node * nd, std::string edge_length_string) {
assert(nd);
bool success = true;
double d = 0.0;
try {
d = std::stod(edge_length_string);
}
catch(std::invalid_argument &) {
// edge_length_string could not be converted to a double value
success = false;
}
if (success) {
// conversion succeeded
nd->setEdgeLength(d);
}
else
throw XStrom(boost::str(boost::format("%s is not interpretable as an edge length") % edge_length_string));
}
The countNewickLeaves member function
This private function counts the number of leaves (i.e. tip nodes) in the tree defined by a newick string. This makes use of the standard regular expression library, std::regex, which comes with C++11. The regular expression pattern (taxonexpr) identifies leaf nodes as integer values preceded by either a comma or a left parenthesis and followed by a comma, right parenthesis, or colon. It also allows non-integer taxon names, and even taxon names containing embedded spaces if they are surrounded by single quotes, even though such newick tree descriptions will ultimately be rejected (see section above on the extractNodeNumberFromName function).
inline unsigned TreeManip::countNewickLeaves(const std::string newick) {
std::regex taxonexpr("[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])");
std::sregex_iterator m1(newick.begin(), newick.end(), taxonexpr);
std::sregex_iterator m2;
return (unsigned)std::distance(m1, m2);
}
The way this function works is concise but admittedly rather opaque. If you are not familiar with how regular expression searches work, you probably should spend some time reading about them before trying to understand this function.
Regular expressions in C++ are complicated by the fact that backslash characters in regular expression patterns must be repeated so that the backslash is interpreted as a literal backslash character and not as an escape character. For example, when the 2-character sequence \n appears in a string, it is interpreted not as 2 characters, but as a single (invisible) new line character: the \ serves to escape the following character (n), which is jargon for treating the n as a special code for new line rather than treating it literally as a lower case version of the character N. A backslash followed by a second backslash yields an escaped backslash, which is just a single backslash! Hence there are many double backslashes (\\) appearing in the string stored as taxonexpr.
It is possible to simplify the regular expression string by telling C++ that you do not want the string to be escaped. To do this, you precede the string with R"( and end the string with )". This approach will be illustrated the next time we encounter regular expressions, in Create the Partition class. There are relatively few backslashes in this regular expression, and wrapping the regular expressions in R"(...)" adds its own complexities, so we will just use the double-slash approach for the present.
Below is a blow-by-blow account of the regex pattern string taxonexpr. You may wish to consult the
Python documentation of regular expression patterns while reading through this explanation.
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^ specifies either a left paren "(" or a comma ","
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^ specifies 0 or more ("*") whitespace characters "\\s"
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^^^^^^^^^^^^^^^^^^^ specifies 3 possibilities (see below)
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^ 1st possibility: 1 or more digits ("\\d+")
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^^ 2nd possibility: 1 or more non-greedy
darkspace characters ("\\S+?")
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^^^^^^ 3rd possibility: a single quote ("[']")
followed by 1 or more non-greedy
characters of any kind (".+?")
followed by a single quote ("[']")
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^ specifies 0 or more whitespace characters
[(,]\\s*(\\d+|\\S+?|['].+?['])\\s*(?=[,):])
^^^^^^^^^ look ahead but do not consume ("?=")
a comma, right paren, or colon
character ("[,):]")
The variable m1 iterates through all taxon names (i.e. matches to the pattern) in the supplied newick string, while m2 is never initialized and thus represents the value that m1 would take if it was iterated past the end of the string. The function std::distance(m1, m2) counts the number of times m1 needs to be incremented until it equals m2, which is the number of taxa in the newick string.
The stripOutNexusComments member function
This private function strips out comments from the newick string. Many programs place special comments inside newick strings that only they understand (e.g. FigTree stores color information about nodes in such comments). Comments in newick strings are delimited by square brackets, so this function uses the C++11 standard library’s regex_replace function to replace all such comments with the empty string. Note that the ampersand (&) in the parameter list means that the newick string is supplied as a reference rather than as a copy. As a result, it is modified in place, which explains why this function does not return the modified string.
inline void TreeManip::stripOutNexusComments(std::string & newick) {
std::regex commentexpr("\\[.*?\\]");
newick = std::regex_replace(newick, commentexpr, std::string(""));
}
The findNextPreorder member function
This function is a helper function that simplifies refreshPreorder (next). It follows _left_child, _right_sib, and _parent pointers to locate the next node in preorder sequence. If a left child exists, then that is the next node in the preorder. Failing that, the right sibling is chosen. If there is neither a left child nor a right sibling, then we are located at the top right corner of a clade and must backtrack down through parents until a right sibling appears (unless we have already visited the last node in preorder sequence, in which case our backtracking will take us all the way down to the root node).
inline Node * TreeManip::findNextPreorder(Node * nd) {
assert(nd);
Node * next = 0;
if (!nd->_left_child && !nd->_right_sib) {
// nd has no children and no siblings, so next preorder is the right sibling of
// the first ancestral node that has a right sibling.
Node * anc = nd->_parent;
while (anc && !anc->_right_sib)
anc = anc->_parent;
if (anc) {
// We found an ancestor with a right sibling
next = anc->_right_sib;
}
else {
// nd is last preorder node in the tree
next = 0;
}
}
else if (nd->_right_sib && !nd->_left_child) {
// nd has no children (it is a tip), but does have a sibling on its right
next = nd->_right_sib;
}
else if (nd->_left_child && !nd->_right_sib) {
// nd has children (it is an internal node) but no siblings on its right
next = nd->_left_child;
}
else {
// nd has both children and siblings on its right
next = nd->_left_child;
}
return next;
}
The refreshPreorder member function
This private function must be called whenever the structure of the tree changes. It rebuilds the _preorder vector by visiting nodes in preorder sequence and storing pointers to these nodes as it goes.
inline void TreeManip::refreshPreorder() {
// Create vector of node pointers in preorder sequence
_tree->_preorder.clear();
_tree->_preorder.reserve(_tree->_nodes.size() - 1); // _preorder does not include root node
if (!_tree->_root)
return;
Node * first_preorder = _tree->_root->_left_child;
// sanity check: first preorder node should be the only child of the root node
assert(first_preorder->_right_sib == 0);
Node * nd = first_preorder;
_tree->_preorder.push_back(nd);
while (true) {
nd = findNextPreorder(nd);
if (nd)
_tree->_preorder.push_back(nd);
else
break;
} // end while loop
}
The function first removes all elements from the tree’s _preorder vector and allocates enough memory to store pointers to all nodes except the root. It returns right away if the data member _root does not point to a node because this can only mean that no tree has yet been built.
The first_preorder variable points to the only child of the root node. This will be the first node pointer added to the _preorder vector. The main while loop is then set to cycle forever (because the constant true is always true!), and only exits when the break keyword is encountered, which only happens after the last node in preorder sequence is visited. The comments inside the while(true) loop explain the decisions needed to determine which node should next be added to _preorder.
The function concludes with a loop that visits each node in postorder sequence. The postorder sequence is simply the reverse of the preorder sequence, which explains the need for boost::adaptors::reverse, which causes the _preorder vector to be traversed in reverse order. The internal nodes are numbered sequentially starting with the number of leaves (_nleaves). This means that no internal node can have a _number equal to any tip node because tip nodes have node numbers ranging from 0 to _nleaves-1. Numbering internals in postorder sequence means that we can use the last number for the root node if the tree happens to be rooted. If the tree is unrooted, remember that the root node is actually a leaf (tip) and thus has a number less than _nleaves.
Why do we even need to number the internal nodes? Later we will use the _number data member of each node as an index into arrays used by the BeagleLib library to compute likelihoods. Thus, it is important that all nodes be numbered and that the numbers are sequential with no gaps.
The refreshLevelorder member function
This function, like refreshPreorder, fills a vector (_levelorder) with Node pointers. In this case the nodes are visited in level order
rather than preorder sequence. Level order dictates that all the nodes at a given level of the hierarchy defined by the tree are visited before any nodes at a higher level. In the example provided in the comment below, the first level considered has only one node, labeled 1. The second level has the immediate children of the single node at the first level, namely nodes 2 and 3. The third level has the immediate children of the nodes on the second level, namely nodes 4, 5, 6 and 7. Finally, the fourth level contains only nodes 8 and 9.
We need a level-order vector when supplying nodes to the BeagleLib library for likelihood calculations. Calculation of partial likelihoods proceeds top-down: child nodes must be processed before their parents. By supplying nodes to BeagleLib in reverse level order, BeagleLib can be processing, in the example below, nodes 4 and 5 at the same time it is processing 6 and 7, thus increasing the efficiency of the overall calculation of partial likelihood vectors. If we were to use a postorder traversal, nodes 4 and 5 would have to wait until node 3 is done, which could not happen until after nodes 6 and 7 are finished.
inline void TreeManip::refreshLevelorder() {
if (!_tree->_root)
return;
// q is the buffer queue
std::queue<Node *> q;
// _tree->_levelorder is the stack vector
_tree->_levelorder.clear();
_tree->_levelorder.reserve(_tree->_nodes.size() - 1);
Node * nd = _tree->_root->_left_child;
// sanity check: first node should be the only child of the root node
assert(nd->_right_sib == 0);
// Push nd onto back of queue
q.push(nd);
while (!q.empty()) {
// pop nd off front of queue
nd = q.front(); q.pop();
// and push it onto the stack
_tree->_levelorder.push_back(nd);
// add all children of nd to back of queue
Node * child = nd->_left_child;
if (child) {
q.push(child);
child = child->_right_sib;
while (child) {
q.push(child);
child = child->_right_sib;
}
}
} // end while loop
}
The renumberInternals member function
This function sets the _number data member of each internal Node object. This needs to be done only when the tree is first built. The internal nodes are numbered in postorder sequence starting with the number of leaves. Note that if the tree has one or more polytomies, not all nodes in the Tree objects _nodes vector will be numbered by a postorder traversal. The final loop takes care of this (in case any of the polytomies end up being resolved later, necessitating the use of these nodes).
inline void TreeManip::renumberInternals() {
assert(_tree->_preorder.size() > 0);
// Renumber internal nodes in postorder sequence
unsigned curr_internal = _tree->_nleaves;
for (auto nd : boost::adaptors::reverse(_tree->_preorder)) {
if (nd->_left_child) {
// nd is an internal node
nd->_number = curr_internal++;
}
}
// Root node is not included in _tree->_preorder, so if the root node
// is an internal node we need to number it here
if (_tree->_is_rooted)
_tree->_root->_number = curr_internal++;
_tree->_ninternals = curr_internal - _tree->_nleaves;
// If the tree has polytomies, then there are Node objects stored in
// the _tree->_nodes vector that have not yet been numbered. These can
// be identified because their _number is currently equal to -1.
for (auto & nd : _tree->_nodes) {
if (nd._number == -1)
nd._number = curr_internal++;
}
}
The canHaveSibling member function
This function is used to check for polytomies (internal nodes with degree > 3; degree means the number of edges radiating from a node). The function first asserts that nd points to something and that the caller is not trying to add a sibling to the root node, which should never have a sibling. If allow_polytomies is true, then canHaveSibling returns true immediately because there is no need to guard against polytomies in this case. Assuming allow_polytomies is false, canHaveSibling returns true if and only if adding a right sibling to nd is allowed (i.e. would not generate a polytomy).
inline bool TreeManip::canHaveSibling(Node * nd, bool rooted, bool allow_polytomies) {
assert(nd);
if (!nd->_parent) {
// trying to give root node a sibling
return false;
}
if (allow_polytomies)
return true;
bool nd_can_have_sibling = true;
if (nd != nd->_parent->_left_child) {
if (nd->_parent->_parent) {
// trying to give a sibling to a sibling of nd, and nd's parent is not the root
nd_can_have_sibling = false;
}
else {
if (rooted) {
// root node has exactly 2 children in rooted trees
nd_can_have_sibling = false;
}
else if (nd != nd->_parent->_left_child->_right_sib) {
// trying to give root node more than 3 children
nd_can_have_sibling = false;
}
}
}
return nd_can_have_sibling;
}
The rerootAtNodeNumber member function
inline void TreeManip::rerootAtNodeNumber(int node_number) {
// Locate node having _number equal to node_number
Node * nd = 0;
for (auto & curr : _tree->_nodes) {
if (curr._number == node_number) {
nd = &curr;
break;
}
}
if (!nd)
throw XStrom(boost::str(boost::format("no node found with number equal to %d") % node_number));
if (nd != _tree->_root) {
if (nd->_left_child)
throw XStrom(boost::str(boost::format("cannot currently root trees at internal nodes (e.g. node %d)") % nd->_number));
rerootAtNode(nd);
}
}
This private member function reroots the tree at the node whose number is supplied, and is intended to be called only in the case of unrooted trees in order to specify the tip node that should serve as the root. The specified node is assumed to exist in the tree and is assumed to be a leaf (it throws an XStrom exception if either of these assumptions turn out to be false). This function loops through all nodes in the tree, letting the temporary variable curr take on each node object in turn. If any node has a _number data member that matches the supplied node_number, the loop breaks and the local pointer nd is set to point to this node object.
The function then tests whether nd points to anything , and if not throws an exception with the message “no node found with number equal to xx”, where xx is replaced by node_number.
Finally, the function tests whether nd is actually already equal to the root node. If that is true, then no work needs to be done. If false, it checks to make sure nd is not pointing to an internal node. If so, it throws an exception. Assuming all is well, it calls the member function rerootAtNode to do the work.
The rerootAtNode member function
The way this function works is to move the target node (the one having _number equal to node_number) down the tree one step at a time until it is at the root position. At each step, the nodes below it are moved up to maintain the branching structure of the tree.
The figure below illustrates the process. (You may wish to print out the PDF version of this figure for reference.)
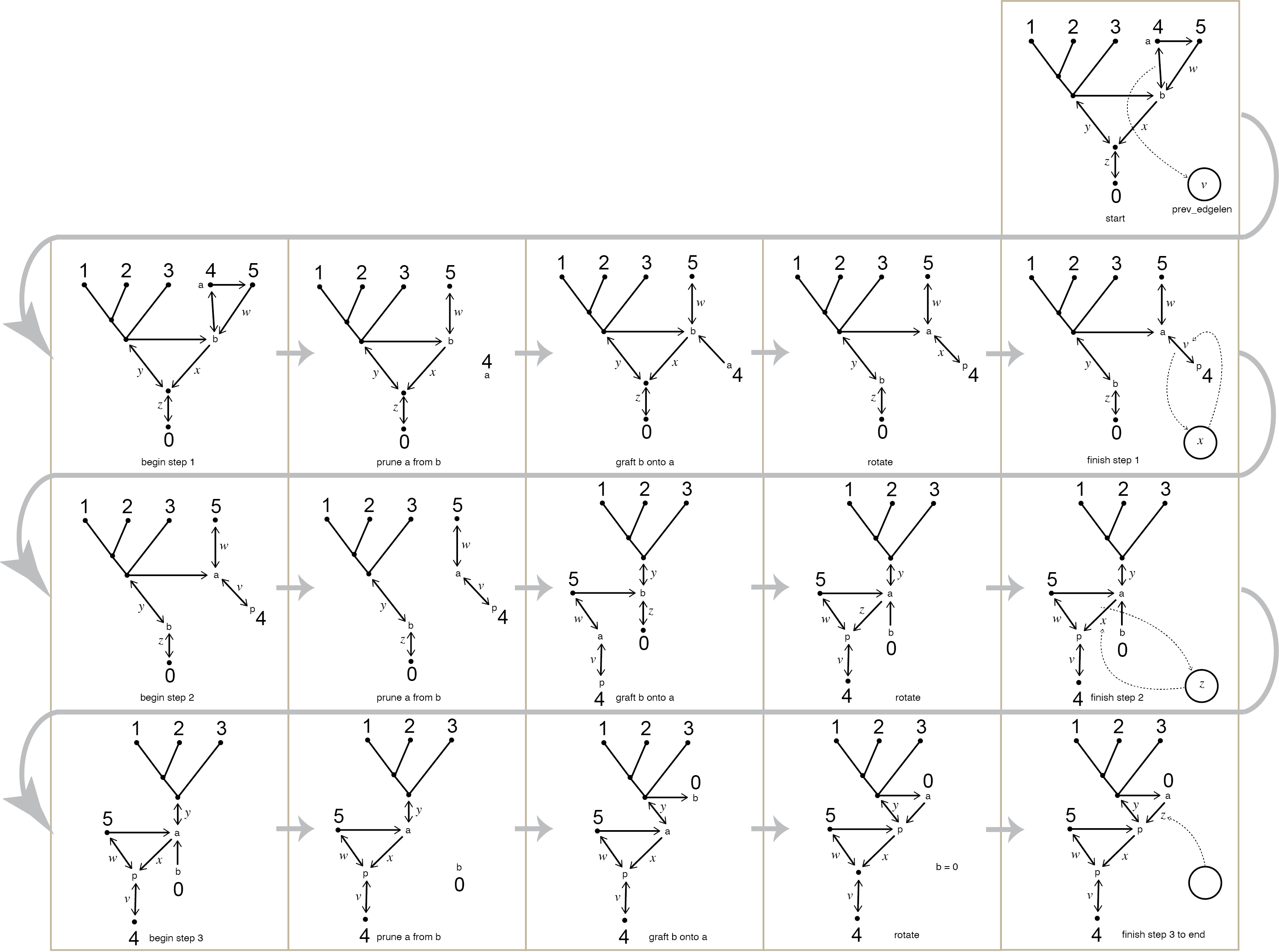
In the figure, the center (second full) column shows the connections between nodes (and edge lengths) after completing the section beginning with the comment “Prune node a from b”. The third full column in the figure shows the connection between nodes after completing the section beginning with the comment “Graft node b onto node a (but don’t unhook node b from its parent just yet)”. The circles in the first full column hold the value currently stored in prev_edgelen. Finally, while advancing from one row of the figure to the next, we carry out the node reassignments in the section labeled with the comment “Rotate”.
inline void TreeManip::rerootAtNode(Node * prospective_root) {
Node * a = prospective_root;
Node * b = prospective_root->_parent;
Node * c = 0;
Node * d = 0;
Node * p = 0;
a->_parent = 0;
double tmp_edgelen = 0.0;
double prev_edgelen = a->getEdgeLength();
while (b) {
// Prune node a from b
if (a == b->_left_child) {
if (a->_right_sib) {
b->_left_child = a->_right_sib;
a->_right_sib = 0;
}
else {
b->_left_child = 0;
}
}
else {
c = b->_left_child;
while (c->_right_sib != a)
c = c->_right_sib;
d = a->_right_sib;
c->_right_sib = d;
a->_right_sib = 0;
}
// Graft node b onto node a (but don't unhook node b from its parent just yet)
if (a->_left_child) {
c = a->_left_child;
while (c->_right_sib)
c = c->_right_sib;
c->_right_sib = b;
}
else {
a->_left_child = b;
}
// Rotate
p = a;
a = b;
b = b->_parent;
a->_parent = p;
// Swap nd's edge length with its new parent's edge length
tmp_edgelen = a->getEdgeLength();
a->setEdgeLength(prev_edgelen);
prev_edgelen = tmp_edgelen;
}
prospective_root->setEdgeLength(0.0);
_tree->_root = prospective_root;
refreshPreorder();
refreshLevelorder();
}
The buildFromNewick member function
Now that all the helper functions are in place, it is time to define the body of the buildFromNewick function.
inline void TreeManip::buildFromNewick(const std::string newick, bool rooted, bool allow_polytomies) {
_tree.reset(new Tree());
_tree->_is_rooted = rooted;
std::set<unsigned> used; // used to ensure that no two leaf nodes have the same number
unsigned curr_leaf = 0;
unsigned num_edge_lengths = 0;
unsigned curr_node_index = 0;
// Remove comments from the supplied newick string
std::string commentless_newick = newick;
stripOutNexusComments(commentless_newick);
// Resize the _nodes vector
_tree->_nleaves = countNewickLeaves(commentless_newick);
if (_tree->_nleaves < 4)
throw XStrom("Expecting newick tree description to have at least 4 leaves");
unsigned max_nodes = 2*_tree->_nleaves - (rooted ? 0 : 2);
_tree->_nodes.resize(max_nodes);
for (auto & nd : _tree->_nodes )
nd._number = -1;
try {
// Root node
Node * nd = &_tree->_nodes[curr_node_index];
_tree->_root = nd;
if (_tree->_is_rooted) {
nd = &_tree->_nodes[++curr_node_index];
nd->_parent = &_tree->_nodes[curr_node_index - 1];
nd->_parent->_left_child = nd;
}
// Some flags to keep track of what we did last
enum {
Prev_Tok_LParen = 0x01, // previous token was a left parenthesis ('(')
Prev_Tok_RParen = 0x02, // previous token was a right parenthesis (')')
Prev_Tok_Colon = 0x04, // previous token was a colon (':')
Prev_Tok_Comma = 0x08, // previous token was a comma (',')
Prev_Tok_Name = 0x10, // previous token was a node name (e.g. '2', 'P._articulata')
Prev_Tok_EdgeLen = 0x20 // previous token was an edge length (e.g. '0.1', '1.7e-3')
};
unsigned previous = Prev_Tok_LParen;
// Some useful flag combinations
unsigned LParen_Valid = (Prev_Tok_LParen | Prev_Tok_Comma);
unsigned RParen_Valid = (Prev_Tok_RParen | Prev_Tok_Name | Prev_Tok_EdgeLen);
unsigned Comma_Valid = (Prev_Tok_RParen | Prev_Tok_Name | Prev_Tok_EdgeLen);
unsigned Colon_Valid = (Prev_Tok_RParen | Prev_Tok_Name);
unsigned Name_Valid = (Prev_Tok_RParen | Prev_Tok_LParen | Prev_Tok_Comma);
// Set to true while reading an edge length
bool inside_edge_length = false;
std::string edge_length_str;
unsigned edge_length_position = 0;
// Set to true while reading a node name surrounded by (single) quotes
bool inside_quoted_name = false;
// Set to true while reading a node name not surrounded by (single) quotes
bool inside_unquoted_name = false;
// Set to start of each node name and used in case of error
unsigned node_name_position = 0;
// loop through the characters in newick, building up tree as we go
unsigned position_in_string = 0;
for (auto ch : commentless_newick) {
position_in_string++;
if (inside_quoted_name) {
if (ch == '\'') {
inside_quoted_name = false;
node_name_position = 0;
if (!nd->_left_child) {
extractNodeNumberFromName(nd, used);
curr_leaf++;
}
previous = Prev_Tok_Name;
}
else if (iswspace(ch))
nd->_name += ' ';
else
nd->_name += ch;
continue;
}
else if (inside_unquoted_name) {
if (ch == '(')
throw XStrom(boost::str(boost::format("Unexpected left parenthesis inside node name at position %d in tree description") % node_name_position));
if (iswspace(ch) || ch == ':' || ch == ',' || ch == ')') {
inside_unquoted_name = false;
// Expect node name only after a left paren (child's name), a comma (sib's name) or a right paren (parent's name)
if (!(previous & Name_Valid))
throw XStrom(boost::str(boost::format("Unexpected node name (%s) at position %d in tree description") % nd->_name % node_name_position));
if (!nd->_left_child) {
extractNodeNumberFromName(nd, used);
curr_leaf++;
}
previous = Prev_Tok_Name;
}
else {
nd->_name += ch;
continue;
}
}
else if (inside_edge_length) {
if (ch == ',' || ch == ')' || iswspace(ch)) {
inside_edge_length = false;
edge_length_position = 0;
extractEdgeLen(nd, edge_length_str);
++num_edge_lengths;
previous = Prev_Tok_EdgeLen;
}
else {
bool valid = (ch =='e' || ch == 'E' || ch =='.' || ch == '-' || ch == '+' || isdigit(ch));
if (!valid)
throw XStrom(boost::str(boost::format("Invalid branch length character (%c) at position %d in tree description") % ch % position_in_string));
edge_length_str += ch;
continue;
}
}
if (iswspace(ch))
continue;
switch(ch) {
case ';':
break;
case ')':
// If nd is bottommost node, expecting left paren or semicolon, but not right paren
if (!nd->_parent)
throw XStrom(boost::str(boost::format("Too many right parentheses at position %d in tree description") % position_in_string));
// Expect right paren only after an edge length, a node name, or another right paren
if (!(previous & RParen_Valid))
throw XStrom(boost::str(boost::format("Unexpected right parenthesisat position %d in tree description") % position_in_string));
// Go down a level
nd = nd->_parent;
if (!nd->_left_child->_right_sib)
throw XStrom(boost::str(boost::format("Internal node has only one child at position %d in tree description") % position_in_string));
previous = Prev_Tok_RParen;
break;
case ':':
// Expect colon only after a node name or another right paren
if (!(previous & Colon_Valid))
throw XStrom(boost::str(boost::format("Unexpected colon at position %d in tree description") % position_in_string));
previous = Prev_Tok_Colon;
break;
case ',':
// Expect comma only after an edge length, a node name, or a right paren
if (!nd->_parent || !(previous & Comma_Valid))
throw XStrom(boost::str(boost::format("Unexpected comma at position %d in tree description") % position_in_string));
// Check for polytomies
if (!canHaveSibling(nd, rooted, allow_polytomies)) {
throw XStrom(boost::str(boost::format("Polytomy found in the following tree description but polytomies prohibited:\n%s") % newick));
}
// Create the sibling
curr_node_index++;
if (curr_node_index == _tree->_nodes.size())
throw XStrom(boost::str(boost::format("Too many nodes specified by tree description (%d nodes allocated for %d leaves)") % _tree->_nodes.size() % _tree->_nleaves));
nd->_right_sib = &_tree->_nodes[curr_node_index];
nd->_right_sib->_parent = nd->_parent;
nd = nd->_right_sib;
previous = Prev_Tok_Comma;
break;
case '(':
// Expect left paren only after a comma or another left paren
if (!(previous & LParen_Valid))
throw XStrom(boost::str(boost::format("Not expecting left parenthesis at position %d in tree description") % position_in_string));
// Create new node above and to the left of the current node
assert(!nd->_left_child);
curr_node_index++;
if (curr_node_index == _tree->_nodes.size())
throw XStrom(boost::str(boost::format("malformed tree description (more than %d nodes specified)") % _tree->_nodes.size()));
nd->_left_child = &_tree->_nodes[curr_node_index];
nd->_left_child->_parent = nd;
nd = nd->_left_child;
previous = Prev_Tok_LParen;
break;
case '\'':
// Encountered an apostrophe, which always indicates the start of a
// node name (but note that node names do not have to be quoted)
// Expect node name only after a left paren (child's name), a comma (sib's name)
// or a right paren (parent's name)
if (!(previous & Name_Valid))
throw XStrom(boost::str(boost::format("Not expecting node name at position %d in tree description") % position_in_string));
// Get the rest of the name
nd->_name.clear();
inside_quoted_name = true;
node_name_position = position_in_string;
break;
default:
// Get here if ch is not one of ();:,'
// Expecting either an edge length or an unquoted node name
if (previous == Prev_Tok_Colon) {
// Edge length expected (e.g. "235", "0.12345", "1.7e-3")
inside_edge_length = true;
edge_length_position = position_in_string;
edge_length_str = ch;
}
else {
// Get the node name
nd->_name = ch;
inside_unquoted_name = true;
node_name_position = position_in_string;
}
} // end of switch statement
} // loop over characters in newick string
if (inside_unquoted_name)
throw XStrom(boost::str(boost::format("Tree description ended before end of node name starting at position %d was found") % node_name_position));
if (inside_edge_length)
throw XStrom(boost::str(boost::format("Tree description ended before end of edge length starting at position %d was found") % edge_length_position));
if (inside_quoted_name)
throw XStrom(boost::str(boost::format("Expecting single quote to mark the end of node name at position %d in tree description") % node_name_position));
if (_tree->_is_rooted) {
refreshPreorder();
refreshLevelorder();
}
else {
// Root at leaf whose _number = 0
// refreshPreorder() and refreshLevelorder() called after rerooting
rerootAtNodeNumber(0);
}
renumberInternals();
}
catch(XStrom x) {
clear();
throw x;
}
}
This function contains a preamble that sets up everything followed by a main loop that does the work of building the tree.
The preamble
The first lines reset the _tree shared pointer so that it points to a brand new Tree object. If _tree had been pointing to a Tree object before, and this was the last shared pointer pointing to that particular Tree object, then the Tree object formerly pointed to would be deleted and its destructor would report “Destroying a Tree” (assuming the output line in the Tree destructor has not been commented out or removed).
Next, several variables used during the process are initialized. The most interesting of these is the used set, which keeps track of the node numbers assigned to leaf nodes. Leaves take their numbers from the values used as names in the newick string, and, in a valid newick tree description, no two leaf nodes will have the same number. It is not good to assume that the newick tree description will be valid, however, so this set is used to ensure that there are no duplicate leaf numbers.
The stripOutNexusComments function is used to strip any comments from the supplied newick string. The resulting commentless_newick string is what will be used to build the tree.
The countNewickLeaves function is used to count the number of leaf nodes in the newick string and and exception is thrown if there are not at least 4 leaf nodes found. The _nodes vector is resized so that it has length twice the number of leaf nodes. This is sufficient to store either a rooted or an unrooted tree. An unrooted tree actually requires 2 fewer nodes than a rooted one, but having the 2 extra nodes means we can easily convert an unrooted tree to a rooted one without having to reallocate the _nodes vector. Note that the node number of all nodes is set to -1, which is not a valid node number; these node numbers will be replaced for each node later.
The tree’s _root data member is set to point to the first node object in the _nodes vector. The local variable curr_node_index is used to store the index of the last Node object assigned in the _nodes vector. If the tree is rooted, a second node is used; this node is the only child of the root node and serves to connect the root node to the remainder of the tree. Thus, the root node is a fake leaf node that does not have any associated data but nevertheless is a node of degree 1 like other leaf nodes.
The flags section is used to store bits that serve as indicators of the last character read from the commentless_newick string. Bits are used for these indicators because that allows for useful combinations created using the bitwise OR operator (|). For example, the variable LParen_Valid is true if either Prev_Tok_LParen or Prev_Tok_Comma are true. Here are the values of these three in binary, assuming an unsigned int is 4 bytes in size (4 bytes = 32 bits):
Prev_Tok_LParen = 00000000000000000000000000000001
Prev_Tok_Comma = 00000000000000000000000000001000
LParen_Valid = 00000000000000000000000000001001
If the variable previous is set to the appropriate flag given the character just read from commentless_newick (e.g. previous = Prev_Tok_Comma if the character just read was a comma), then a bitwise AND operator (&) can be used to determine whether it is valid that the next character is a left parenthesis:
if (!(previous & LParen_Valid))
throw XStrom("Not expecting left parenthesis at position in tree description");
Read more about bitwise operations if the previous explanation does not make sense to you.
The remaining lines in the preamble create variables for recording whether we are currently reading a node name or an edge length.
The main loop
The main loop begins with the line
for (auto ch : commentless_newick) {
The variable ch holds the current character, and various actions are taken depending on the value of ch. If we are currently reading a node name or an edge length, then ch is appended to the growing node name or edge length string. Assuming we are not reading a node name or edge length, and assuming ch is not whitespace, we enter a switch statement comprising cases for characters that may appear inside a newick string, such as a left parenthesis (which leads to creation of a left child), a comma (which leads to the addition of a right sibling), a right parenthesis (which causes us to fall back to the ancestor of the current node), a colon (which signals the beginning of an edge length), or a single or double quote (which signals the beginning of a node name containing embedded spaces or characters that have meaning inside a newick string).
After the main loop
After the main loop has finished (because a terminating right parenthesis was encountered), unrooted trees are rooted arbitrarily at the leaf node whose number is 0. The functions refreshPreorder and refreshLevelorder are called to ensure that the tree can be navigated correctly using the _preorder and _levelorder vectors, respectively.